What I actually set out to build
I wanted to build a chatbot grounded in my own truth, not another thin wrapper over an LLM API. I was not interested in shipping a polished UI where the only technical story is that I connected a model endpoint and formatted the output. I wanted first-person recruiter answers backed by my own notes and project history, with citations and hard guardrails against hallucination.
I built and tuned the system locally first: ingestion and chunking, semantic retrieval behavior, intent routing, and confidence thresholds. I did not fine-tune a base foundation model from scratch. I tuned the application layer that decides when to retrieve, when to synthesize, when to cache, and when to refuse. Once the behavior was stable, I handed embedding and generation workloads off to Runpod endpoints so the same grounded behavior could run with better operational cost and latency controls.
The assistant is live at ellojesse.com. Ask it about my experience, projects, stack, or how I make engineering tradeoffs.
The constraint that shaped it
I started with a portfolio chatbot for recruiter-style questions, but the real problem was narrower and harder: answer in first person from my actual notes, cite the supporting evidence, and fall back when the evidence was weak.
That constraint forced real engineering decisions across ingestion quality, chunking, semantic retrieval, confidence thresholds, caching policy, regression control, infrastructure cost, and route-level observability.
The actual problem to solve
People do not ask one canonical prompt. They ask infinite variations:
- What tech stack have you worked with?
- What stack do you have the most experience with?
- What have you shipped in production?
If the system is too strict, obvious questions miss. If it is too loose, unrelated prompts collide and return wrong content with confidence. So the core challenge was not one good answer. It was stable correctness across language variation without turning the project into regex whack a mole.
A concrete example
Here is the kind of request path I wanted the system to handle cleanly. The question sounds simple, but the answer should come from the right evidence instead of whatever chunk happens to look close.
What stack are you strongest in?
recruiter_stack_experience
Recruiter Q&A, project notes, and production experience summaries.
Use a high-confidence recruiter path, then answer from grounded context.
What I built
I moved to a hybrid architecture:
- Deterministic fast paths for proven stable intents
- Semantic retrieval for open phrasing
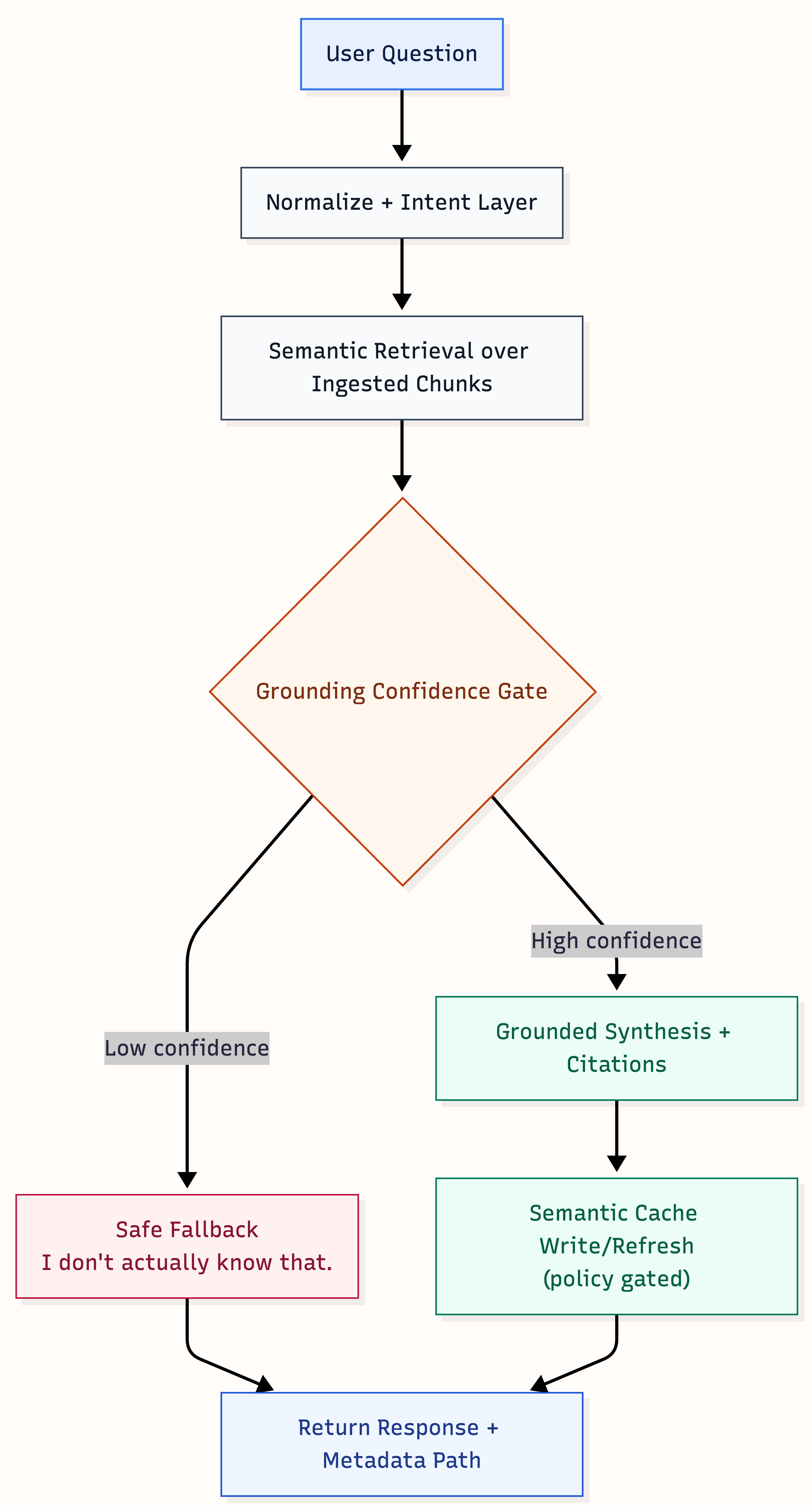
- Grounding confidence gate before synthesis
- Semantic cache for high confidence reuse
- Strict fallback when confidence is below threshold
- Response path metadata for observability and regression triage
Architecture overview
There are two flows that explain how the system works. The first shows the answer pipeline: how a recruiter question moves through retrieval, confidence gating, synthesis, fallback, and metadata logging. The second shows the route-level decision tree that helped me understand latency and optimize the system without weakening grounding quality.
Why the benchmark mattered
I ran a benchmark because I did not want to optimize based on vibes. A few prompts can make a system feel solid, but they do not prove it behaves well across phrasing variation, route types, and cache states.
The benchmark gave me route level truth: where the system was fast, where it was slow, and what I could safely optimize next without weakening the grounding behavior.
This was a small production-safe benchmark, not a formal load test. It was still useful because it showed route-level latency patterns and pointed to the next optimization target.
What the benchmark actually showed
The benchmark used a 40 request production safe run. I was not trying to prove the system was perfect. I wanted to answer a more practical question: when people ask similar questions in different ways, can the system stay grounded while getting faster?
The topline result was yes. Cache enabled mode was materially faster in mixed traffic, and the biggest win showed up in tail latency. In plain English, tail latency is the slow end of the experience: the requests that make a user wonder if something is stuck.
Mean latency improved 28.1%, which means the average request got meaningfully faster. I also tracked p90, which means 90% of requests finished at or below that number, while the slowest 10% took longer. I used p90 because averages can hide painful outliers. A chatbot can feel fast most of the time, but if the slowest common requests drag, users still experience it as unreliable.
That is why the p90 drop mattered: it went from 3505.2 ms to 2092.4 ms. The system was not only faster on average; the slow end of the user experience became much less painful. The median moved less because this was not a cache only workload. Some requests were already fast deterministic paths, while many still went through slower direct canonical paths.
Route breakdown
The route-level view was the most useful part of the benchmark. Cache hits averaged 212.8 ms, deterministic fast paths averaged 264.2 ms, and direct_canonical requests averaged 2726.9 ms across 19 requests. That showed me the cache was working; the blended average was being pulled up by the fuller generation path.
The next optimization target was clear: move repeatable, high-confidence prompts out of direct_canonical when the evidence is strong enough, then keep watching cache hit rate, direct_canonical_share, and p90_by_route after each deploy.
Tech stack and why I chose it
The stack was intentionally explicit: Next.js and TypeScript for clear API boundaries, Postgres and Prisma for reliable state, Nomic embeddings for paraphrase-heavy recruiter questions, Runpod endpoints for cost control, and route metadata plus regression checks so I could change routing logic without silently breaking grounded behavior.
Cost and latency considerations
I noticed Runpod spend climbing before the assistant was fully live because semantically similar recruiter questions were still triggering fresh generation. That pushed semantic caching from nice-to-have into core infrastructure.
The dollar savings are modest at low volume, but the tradeoff still made sense: cache coverage reduces repeated GPU work, and the latency gain is immediate. The economics get more meaningful as request volume grows.
Pitfalls and decision signals
- Deterministic first handling did not scale across language variation.
- Global mean alone hid route-level performance truths.
- Strict fallback policy was required to reduce hallucination risk.
- Broad AI coding edits increased regressions and token burn. Constrained scope workflows performed better.
- Cost and latency had to be modeled together, not as separate concerns.
How I kept the codebase shippable
I used AI coding tools, but I did not treat generated code as done. My loop was narrow change, targeted verification, local build, push, deployment check, and then another pass only if the behavior actually improved.
I also used CodeRabbit as an independent review layer. I think of tools like this as modern code linters, but with a wider lens than indentation, style patterns, or basic static checks. The useful part is that they can review intent: possible bugs, design drift, missing tests, unclear documentation, and standards that are easy to skip when you are moving quickly.
For this project, that meant using CodeRabbit to help enforce TSDoc coverage for the functions that carry real system behavior. I am a big believer in documented code, and I do not fully buy the idea that good code simply documents itself. Better code is readable, but it also explains the purpose, constraints, inputs, outputs, and edge cases of the important pieces.
That saved time in the places that matter. I could spend less energy manually hunting for documentation gaps or review hygiene issues, and more energy on behavior: whether the assistant stayed grounded, whether the benchmark still passed, whether the build shipped cleanly, and whether the live site reflected the change.
Closing
I did not just build a chatbot that can talk. I built a grounded system that can justify what it says, refuse when it should, and improve cost and latency through controlled reuse.
The biggest lesson was simple: a strong AI product is not the one that always answers. It is the one that answers when evidence is strong, proves it, and safely declines when it is not.
This project reflects how I like to build: start with a real product constraint, make the system observable, document the decisions that matter, test the behavior users will feel, and optimize only after I understand the failure modes.